You just wanna attention, you don’t want my love.
Attention Is All You Need
https://arxiv.org/pdf/1706.03762.pdf
Motivation / Abstract
目前主导的sequence transduction model 主要都基于复杂的循环、卷积神经网络,通常他们包括encoder和decoder,有些很先进的模型也用attention机制结合了 encoder和decoder。这个团队提出一个网络结构,叫Transformer,并且只基于attention(based solely on attention,听起来很nb)。这个团队的实验表明在两个机器翻译任务上取得了更好的效果,并且模型的训练更加parallelizable、训练需要时间少.
Introduction
paper里这一部分写了一些关于computation efficiency的东西,比如难以并行,比如加上一些factorization trick 和 conditional computation 后提升了性能,然而fundamental constraint remains。attention机制则不需要考虑input 和output里距离较远的dependency(==具体什么意思?==),少数情况下attention 机制和循环神经网络一起使用。
有句话说的很强,说transformer是一个不再使用recurrence而全部依赖attention的机制,并凭借这个描绘出input 和output 间全局的dependencies。Transformer可以更大限度地使用并行,在8个P100 GPU上训练12小时,可以提升翻译任务的质量。
Background(暂时跳过先)
简单说了Transformer的性能、self-attention是用来计算一个sequence的representation。然后说Transformer是第一个只依赖于self-attention 的 transduction model(而不使用sequence aligned RNN 或者卷积)。
Model Architecture (Transformer)
现有的很多transduction model都会有encoder-decoder的结构,encoder把输入的一个symbol组成的序列encode成一个有实数代表的representation $z$,然后decoder就拿着这个 $z$ 再生成一个(由symbol组成的)序列,具体生成的时候是一个symbol一个symbol生成的。Transformer也是类似的结构。
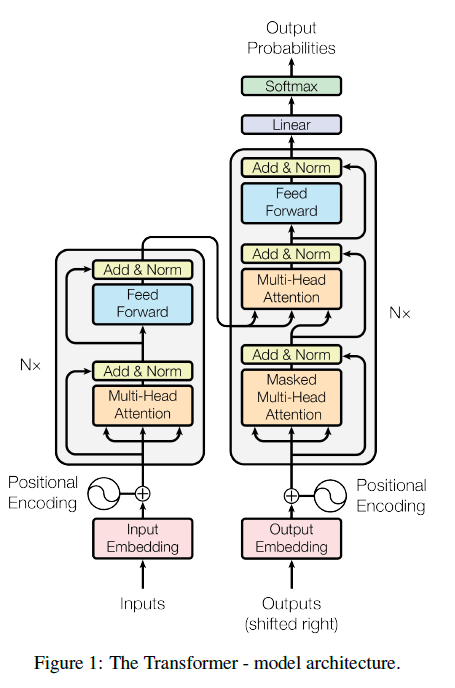
Attention (Figure 1 中橙黄色方块,这个其实就是self-attention)
attention的功能可以看作是建立一个映射:(a query, a set of key-value pairs)-> output,这里的query,keys,values和output都是vector,其中output是values的加权求和,权重的计算由query和相应的key决定。这个query,key,value到底都是什么、怎么算出来的、代表什么,很多博客里都直接认为读者已经懂了,没有讲解这几个问题,但是对seq-to-seq领域比较陌生的我,费了亿点点力,去弄了个明白,就也记在这里了(参考一篇解释的很详细的讲解The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. (jalammar.github.io)):
- 先从这张图理解下这三个概念
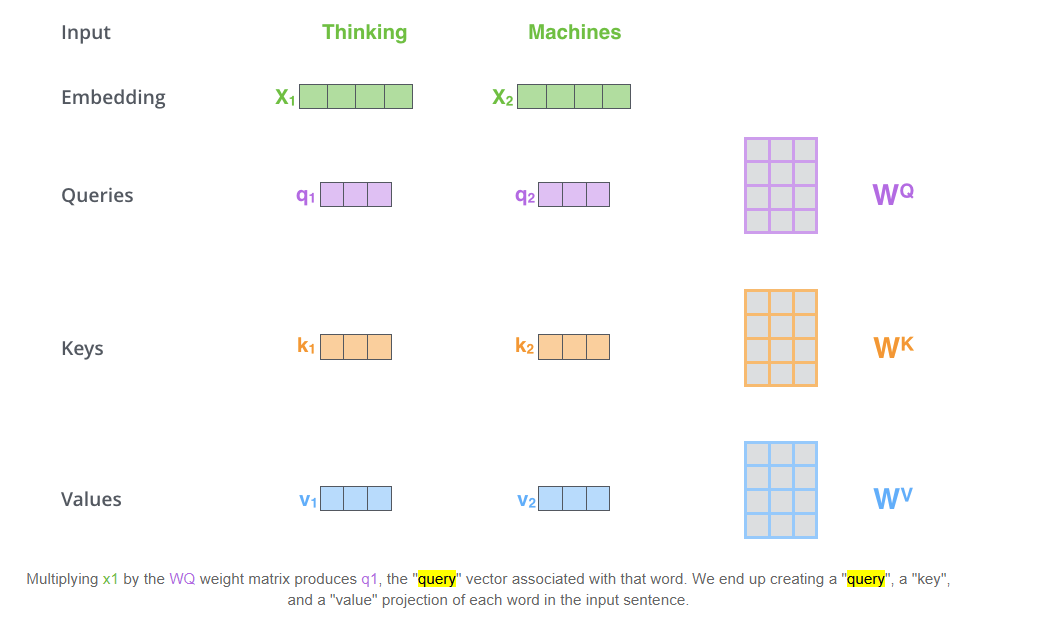
- 输入句子是“Thinking machines”,X是word embeddings,然后这里有三个矩阵,作用可以看作就是维度变化,将word embedding 的维度变到较小的维度,(并不一定非要更小,这是个模型的设计问题)
- 可以看到这三个量在最开始计算出来时,完全是一个模子出来的,关键的是我们怎么理解他们
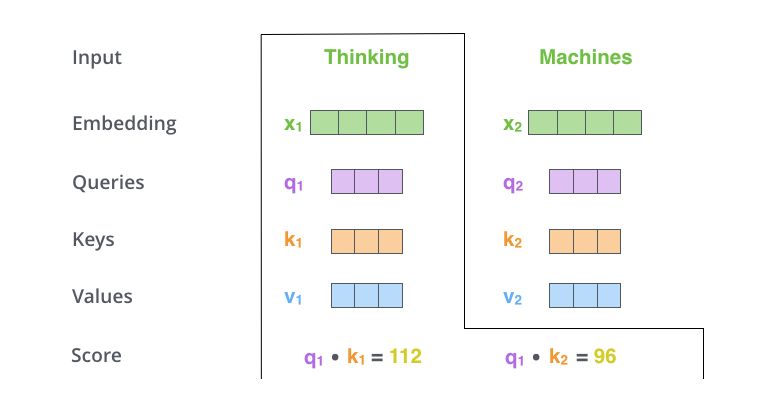
- 从这张图就可以大概理解 query和 key 两个东东是干嘛的了,query 就是用来和 input 句子中其他单词的 key 依次做内积得到分数用的,key 的作用也是相应的,这个分数,其实是 attention 机制的一个精髓,它(被期望)代表这个单词和哪个单词在高维空间更相似,与谁越相似,我们在encode这个单词的时候就更看重谁的 value 向量(所以这里顺带理解一下value向量,就是像一个代表了这个词含义的向量)。
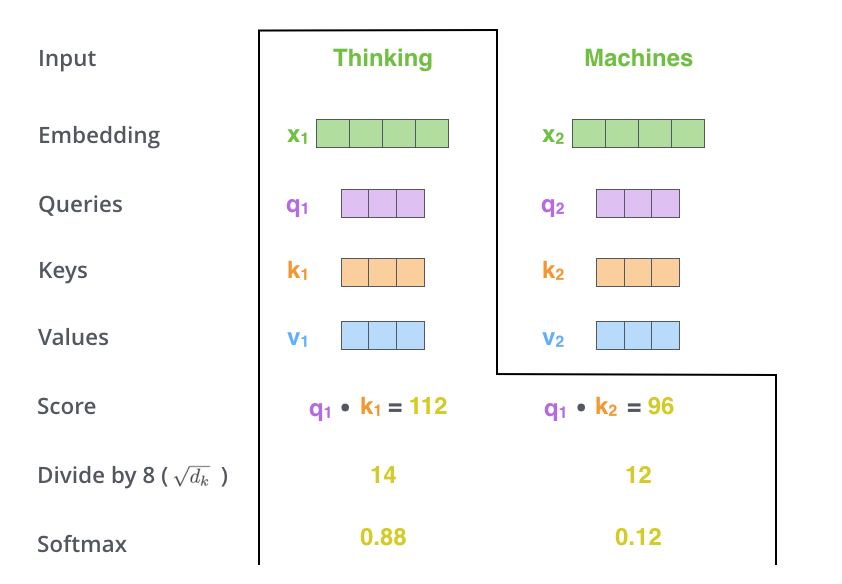
- 这一步就是将分数scale、再用softmax变成分布,scale的目的是让分数尽量平滑一些,换句话说也是让softmax之后的分布更平滑一些。(paper中将 $d_k$ 设为了 64,所以就是将这个分数除以$\sqrt{64}$)
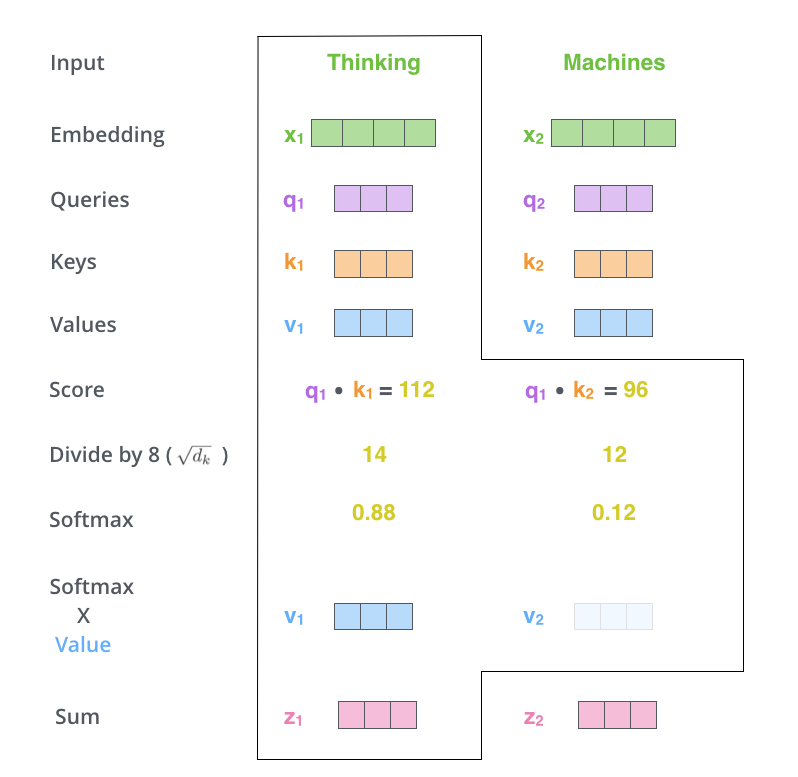
- 这一步就很自然了,用上一步算出的分布当作权重,乘上各个单词的 value,算出各个单词的新 representation。
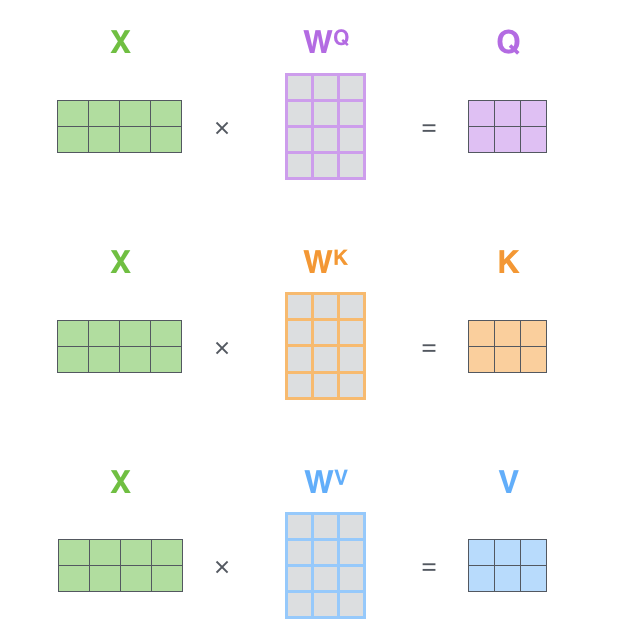
- 实际中,为了效率,我们将这一过程矩阵化,也就有了相应的 query,key和 value的定义。对应下图中$Q, K, V$ 矩阵。
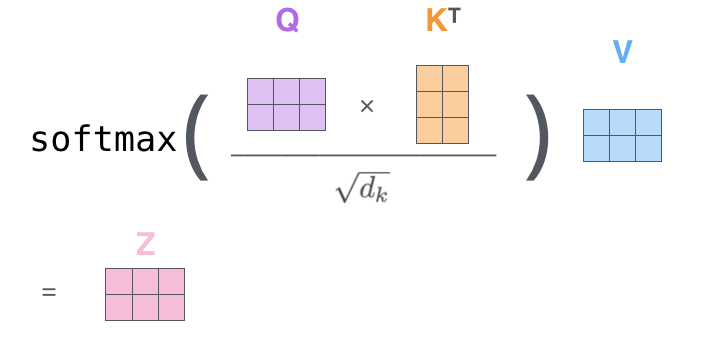
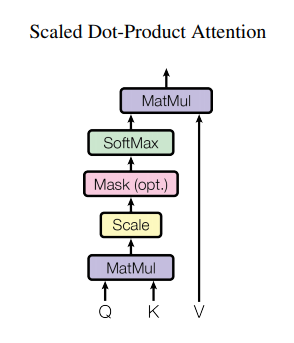
Scaled Dot-Product Attention
Google 把这个叫做Scaled Dot-Product Attention的东西,其实就是上面3.2计算粉色Z矩阵的过程。原paper就用这张图和几句话概括了。
Multi-Head Attention
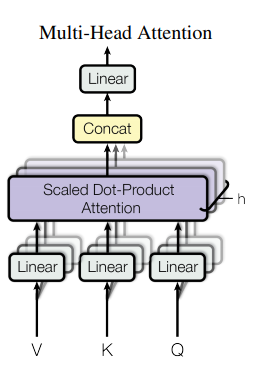
也就是将上面计算 attention 的步骤复制多次(paper里做了8次),那些转换维度的矩阵参数各不相同(shape 当然都是一样的),最后concatenate 起来 再经过一个大的Linear 转换,结束整个encoder部分
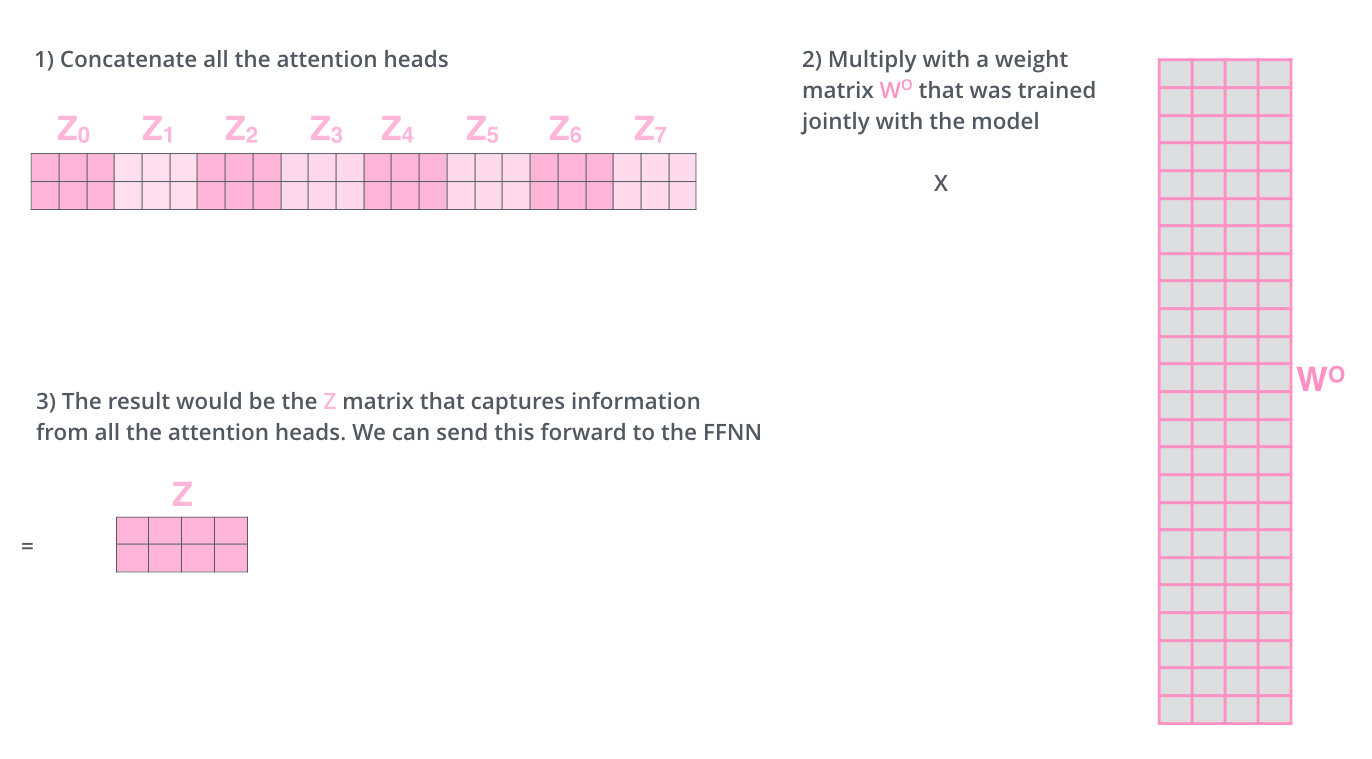
where
\[head_i = Attention(QW^Q_i , KW^K_i , VW^V_i )\]and
\(W^Q_i, W^K_i \in R^{d_{model} \times d_k}, W^V_i \in R^{d_{model} \times d_v}, W^O \in R^{hd_v \times d_{model}}\)
取值:$d_k = d_v = d_{model} / h = 64, h=8$
Encoder (Figure 1 左侧)
encoder由6个完全相同的层组成,每层有两个sub-layer,sub-layer 1是一个multi-head self-attention,2是一个简单的position-wise的全连接。另外还在这两个sub-layer后面各用了一个residual connection的东西,再加一个norm。(==关于residual 和 position embedding还没提,较为简单==)
Decoder (Figure 1 右侧)
decoder也是由6个相同的层组成,相较encoder部分,这里加入了第三个sub-layer,作用是在encoder的输出上做一个multi-head attention。在output 部分的self-attention上有一个mask的步骤,这个是说在预测第 $i$ 个单词时,为了让output不受第 $i$ 个单词之后的影响,在做Q和K内积之后的那个softmax之前将矩阵后面部分设为$-inf$(我的理解是不是说,在test阶段,我们因为没法知道后面的句子是什么,所以在训练时也要保持一致?这像是一个硬性的限制,但paper里只说:This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$.)。最后的linear和softmax也很显而易见了,预测一个词表大小的向量,看看哪个词概率最高,就选这个词作为当前时刻的预测。
写在后面
- self-attention at high level
- self-attention 到底是个怎么样工作的机制呢,从一个简单的例子看看。比如有一句话The animal didn’t cross the street because it was too tired, 这个句子中的 it ,作为一个人我们很清楚这个句子中的 it 指什么,但这个问题算法却不容易搞得清楚。self-attention 就给了模型将it 与 the animal 联系起来的基础,为什么说基础是因为我觉得,self-attention 并不保证模型能发现这个关系,但在训练正确的情况下,或者说理想的情况下,模型可以依靠self-attention做到。
