刚开始接触循环神经网络的时候,还没弄懂LSTM和GRU,总是在网上看到“一篇文章看懂LSTM”这种文章,但其实这种文章我看了5678篇也没看懂过。这种经常理解了就忘了,记下来自己以后看。
记录一下对LSTM and GRU的理解和pytorch用法
先定义一些符号:第 $t$ 时刻输入 $x_t$ (一般是一个vector) , 隐变量$h_t$(一般也是一个vector),$W, U$都是权重矩阵,上标只是为了表明他们不是同一个矩阵而起的不同的名字。$\sigma$ 是sigmoid激活函数,$\circ$ 代表elementwise相乘。
一开始,我们手中所有的输入:一个句子,{$x_1, x_2, \cdots,$} (也可以是很多个句子啦)。一个随机初始化的第0时刻的隐变量 $h_0$(有时候也会人为初始化)
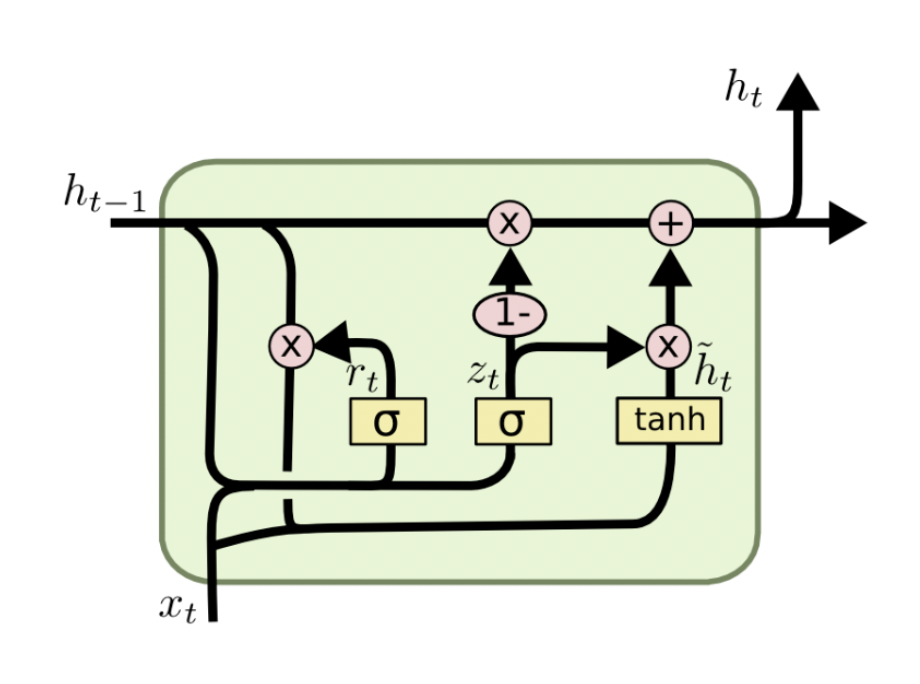
GRU
GRU 的第一个gate:update gate:
\[z_t = \sigma(W^{(z)}x_t + U^{(z)}h_{t-1})\]用 $x_1$ 和 $h_0$,就可以计算出第一个update gate 的输出$z_1$, 类似的要是想要继续计算$z_2$,我们还需要$h_1$, ($x_2$ 已知了),$h_1$怎么算后面会提到。
GRU 的第二个gate:reset gate:
\[r_t = \sigma(W^{(r)}x_t + U^{(r)}h_{t-1})\]计算过程和update gate是一样的,只是用到的权重矩阵不同了。(为什么要算两个这么类似的东西?–因为它们各自被期待完成不同的工作)。
计算 $h_t$
先算一个叫 $\widetilde{h_t}$ 的东西:
\[\widetilde{h_t} = tanh(Wx_t + r_t \circ Uh_{t-1})\]可以理解为我们要对前 $t$ 个时刻的东西做个“小总结”,可以从一个极端情况理解,如果 reset gate 的结果 $r_t$ 很多位置都接近0,那么这个前 $t$ 个时刻的“小总结”就想要忽略之前的状态而只关注第 $t$ 个单词的信息。(为什么要有这个步骤呢?–比如我们在做情感分析任务,有一段电影影评,这段影评先大致描述了一段无聊的剧情,然后最后说it’s boring,那么前面那段剧情对我们其实意义不大,只是最后的这个boring非常重要,可以分析出负面的情感,所以有时候我们想要“忽略”之前的信息,而更关注当前的新东西)。然后再计算 $h_t$:
\[h_t = z_t \circ h_{t-1} + (1-z_t) \circ \widetilde{h_t}\]这里就用到了update gate,不难理解,update gate就是在帮我们决定是否要将刚刚我们计算出那个”小总结“纳入第 $t$ 时刻的隐变量,(或者说纳入多少比例更合适)。也可以从极端情况理解,如果 $z_t$ 处处接近0,那么代表,模型非常愿意将之前计算的”小总结”当作第 $t$ 时刻的隐变量(比如我们看到了boring这个词),反之如果$z_t$ 处处接近1,那么就代表模型更愿意延续刚刚 $t-1$ 时刻的隐变量,他几乎可以复制 $t-1$时刻模型的输出(比如我们看到了a, the这样意义不大的单词)。当然一般的情况,update gate的结果不会”处处”是1或0,他会有选择地关注某些维度。
这些我们提到的 gate 的功能,并不是一开始模型就有的,而是经过训练、我们“希望”模型学到的东西,这里这么设计网络也是给模型一个学到这些东西的空间和基础而已。
GRU总结
GRU被创造出来的原因是为了解决标准RNN梯度消失的问题,解决的关键就是上面提到的两个gate,这两个gate给了模型能够“记住很久之前信息”的能力,GRU也可以看作是LSTM的一个变种。
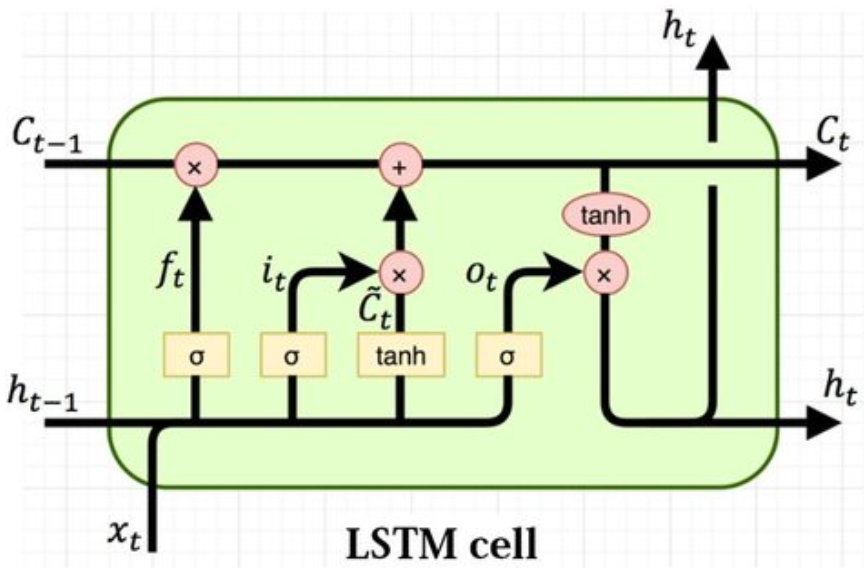
LSTM
说到LSTM,相比传统RNN 和 结构较为简单的 GRU 相比,它多了一个叫cell state($c_t$) 的东西,它就是建立long-short memory 的关键。下面会讲解它是怎么计算出来的,以及为什么可以有对过去的记忆。
LSTM 第一个gate:input gate:
\[i_t = \sigma(W^{(i)}x_t + U^{(i)}h_{t-1})\]input gate 的作用可以看作是它在决定“关心当前词向量”的程度。比如如果模型看到了一个不重要的单词,那么这时候的 $i_t$ 就大概率处处接近0。
LSTM 第二个gate:forget gate:
\[f_t = \sigma(W^{(f)}x_t+U^{(f)}h_{t-1})\]forget gate 的作用可以看作是它在决定遗忘之前信息的程度,如果他处处接近0,则代表模型想要忘掉之前的信息,而开始更关注当前的。
LSTM 第三个gate:output gate:
\[o_t = \sigma(W^{(o)}x_t+U^{(o)}h_{t-1})\]output gate 计算出的内容将决定输出当前cell state的哪些内容。
计算当前时刻的cell state $c_t$
在计算当前时刻的cell state 前,先计算一个对当前时刻信息的总结$\widetilde{c_t}$,
\[\widetilde{c_t} = tanh(W^{(c)}x_t+U^{(c)}h_{t-1})\]然后用上之前算出的forget gate 和 input gate,
\[c_t = f_t \circ c_{t-1} + i_t \circ\widetilde{c_t}\]这个就是第 t 时刻的 cell state了,可以看到它是当前 cell state 和之前 cell state的汇总。
计算当前时刻的hidden state $h_t$
\[h_t = o_t \circ tanh(c_t)\]这里再补充一下关于sigmoid 函数和 tanh 函数的深层含义,我们可以把sigmoid 函数看作一个比例(它的值域在0-1),它往往用来决定某某信息量的比例。tanh 则直接代表信息量的幅值(值域在-1到+1),加一个tanh我认为既有将这个信息量标准化一下防止它过大过小的作用,也有增加非线性,提高模型表达能力的作用。
LSTM 总结
pytorch中的nn.LSTM和nn.GRU
这里举一个双向LSTM的例子:有些地方很繁琐,稍不注意就会犯错。
import torch
from torch import nn
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
class BiLSTM(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(BiLSTM, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.BiLSTM = nn.LSTM(input_size=self.input_dim, hidden_size=self.hidden_dim, num_layers=1, bidirectional=True, batch_first=True)
def forward(self, _input, lengths):
packed_input = pack_padded_sequence(_input, lengths, batch_first=True, enforce_sorted=False)
packed_output, (hn, cn) = self.BiLSTM(packed_input) #这里也可以传入手动初始化的h0和c0,如果不传入,就会用0向量自动初始化。
output, _ = pad_packed_sequence(packed_output, batch_first=True)
# pack_padded_sequence()就是将长度不一的input用一种更简洁的方式打包,便于网络处理,这里就不展开这个packed_input的内部构造了。
# enforce_sorted参数默认是True,代表输入的长度有没有排好序,这里我们并没有排序,所以设置False。
#这一步和pad_packed_sequence()是绑定的,但如果你的输入全部长度都一样,那也没有必要做这两步。
print(output.shape) # torch.Size([5, 9, 4]) (batch size, max input lengths(注意这里是9不是10), num_direction*hidden dimension)
print(hn.shape) # torch.Size([2, 5, 2]) (因为我们设置了双向LSTM,nn.LSTM()参数num_layers是1,所以第一个维度是2,否则将会是num_layers*单/双向)
print(cn.shape) # torch.Size([2, 5, 2]) 同上hn
# 检查output中,对应长度的forward score是否就是hn
for b in range(B):
print(output[b, lengths[b]-1, :self.hidden_dim] == hn[0, b, :])
# 检查output中,对应长度的 backward score是否就是hn,这里注意:
# 1. output中 seq_len维度取的第一个维度,而不是lengths对应的输入长度值
# 2. output中 hiddenb dim维度取得后一半
for b in range(B):
print(output[b, 0, self.hidden_dim:] == hn[1, b, :])
return output, (hn, cn)
if __name__ == '__main__':
model = BiLSTM(input_dim=3, hidden_dim=2)
global B
B = 5
seq_len = 10
input_dim = 3
_input = torch.rand(size=(B, seq_len, input_dim))
# 这里我习惯把batch size维度放在第一个,所以上面定义BiLSTM的时候,要设置batch_first=True(默认是False哦)
# 模拟输入的长度并不一定都相等的情况,比如第一个输入长度是9,第二个输入长度只有2
_input[0, 9:, :] = 0
_input[1, 2:, :] = 0
_input[2, 3:, :] = 0
_input[3, 1:, :] = 0
_input[4, 6:, :] = 0
lengths = torch.tensor([9, 2, 3, 1, 6])
output, (hn, cn) = model(_input, lengths)
GRU和LSTM类似,只是输入输出中都没有$c_n$.
如果有错误请告诉我 :)