本来在看Attention is all you need,太多地方看不懂,来看这篇了
Neural Machine Translation By Jointly Learning to Align and Translate
Abstract / Motivation
(在2016年)用神经网络做翻译很广泛,但一般做法是用encoder-decoder将输入先encode成一个固定长度的vector,然后decoder从这个vector生成翻译后的文本,这篇paper怀疑这是提升翻译任务性能的一个bottleneck,为解决这个,他们在原有翻译模型上进行扩展,让模型自己搜索与目标词语相关的原句子部分,(为了叙述方便,这里我们假设在做英语-法语的翻译任务),也就是然模型能够自己发现C’est la vie(=That’s life.)这句话中 vie对应英文中的life。
Introduction
上述方法中的一个潜在问题就是,神经网络要有把一个长长的句子中的信息全部压缩到一个固定长度的vector中的能力,并且句子较长时这招也就不好使了(已有paper证明这点 Cho et al. (2014b)。
解决方法、也是工作重点:“The most important distinguishing feature of this approach from the basic encoder–decoder is that it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation”
Backgroud
回忆一下经典做法
RNN Encoder-Decoder
用RNN最后一个时刻的hidden state作为context vector $c$,用 $c$ 和前 $t-1$ 时刻的输出作为condition预测第t个单词。(其中一种做法)
Learning to align and translate
Bidirection RNN (encoder) + Decoder (emulates searching)
3.1 Decoder
先说了decoder,定义关于第$i$个输出target单词的条件概率,
\[p(y_i|y_1, \cdots, y_{i-1}, x) = g(y_{i-1}, s_i, c_i)\]where
\[s_i = f(s_{i-1}, y_{i-1}, c_i)\]$s_i$是RNN第 $i$ 时刻的hidden state(感觉这里是人为把 $s$ 叫做了hidden state),这样算出来。这个 $g$ 和 $f$ 在paper appendix里面写了详细公式。
注意这里的 $c_i$ 是针对各个时刻句子context 信息,而不是句子的整体vector。$c_i$由一系列annotations($h_1, \cdots, h_{T_x}$)决定,$h_i$由包含输入句子第 $i$ 个位置附近的东西的信息。(这个$h$ 其实就是Bi-RNN hidden states的 concatenation,3.2说)
$c_i = \sum_{j=1}^{T_x} \alpha_{ij}h_j$, $\alpha_{ij}$就是对应$h_j$的权重,$T_x$ 指句子$x$的长度。
\[\alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}\] \[e_{ij} = a(s_{i-1}, h_j)\]$a$ 是一个网络
对$e_{ij}$直观的解释:他衡量了input句子 $j$ 位置与output句子 $i$ 位置对照的好不好,由RNN第 $i-1$ 个hidden state和第 $j$ 个annotation计算出来。这里的 $a()$ 是一个神经网络,跟随其余网络参数一同训练。这里与以往不同的是,原句子和目标句子的对齐的这个指标不再是隐式的,这个model直接计算出一个soft的alignment。后面paper里给出了较为直观的解释:可以理解为计算annotations的一个加权和,作为expected annotation,这个期望是在可能的alignments上的。$\alpha_{ij}$ 就可以理解成一个单词 $y_i$ 是由 $x_j$ 翻译而来的概率,换句话说就是他们两个是“对齐”的。第 $i$ 个context vector $c_i$ 也就是用 $\alpha$ 这样加权求和算出来的了。
$\alpha_{ij}$(或者说$e_{ij}$) 也就反映了annotation $h_j$ 连同 $s_{i-1}$ 在决定下一个state $s_i$ 和生成 $y_i$ 的重要程度。直觉上看,这里就在decoder内部实现了一个attention,这个decoder决定了翻译时要注重source sentence的哪个部分。以此减轻encoder的工作负担(将一个句子encode到一个fixed-length vector),
3.2 Encoder (bidirectional RNN for anntating sequences)
解决之前 $h$ 怎么来的问题。使用双向RNN,
\[h_j = [\overrightarrow{h_j}; \overleftarrow{h_j}]\]两个箭头 $h_j$ 分别是双向RNN在读取句子第 $j$ 个时刻的forward 和 backward hidden state。(这么简单还搞得神秘兮兮的)
Experiment Settings
数据集:WMT14,English-to-French translation.
一些模型的参数设定,以及模型训练好之后使用beam search找到最大化条件概率的translation。
Result
定量结果
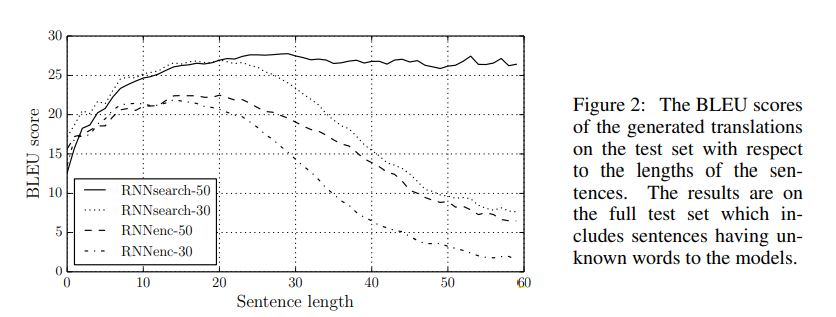
RNNsearch是模型的名字,-50是指在长度最长为50的句子的训练集上训练,看得出在长句子上这个模型能保持翻译的性能不下降,性能由BLEU score代表。
定性结果
这里定性地看一看上面提到的 $\alpha$,也就是衡量source sentence和target sentence中词语的对照关系 ,图片很直观。白色代表strong weights。
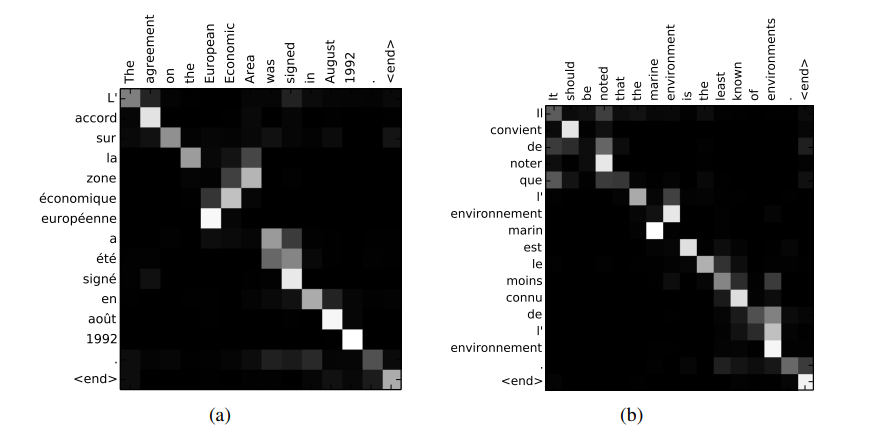
差不多就这些吧,略过了一些网络内部的设计艺术,以后有需要再研究。