2020.12.05 一篇文章读不懂BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/abs/1810.04805
Abstract
- 与以往不同的是,BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers.
- 再加一个额外的output layer就可以变成解决各类问题的state-of-art-的模型。然后还讲了一些在各类任务上的性能提升。
Introduction
- (一些额外的知识)目前用 pre-trained language representation 解决下游任务一般有两个办法,feature-based 或fine-tuning。
- feature-based 例子,ELMo,uses task-specific architectures that include the pre-trained representations as additional features.
- fine-tuning 例子,OpenAI GPT,用minimal 的跟任务相关的参数数量,然后通过下游任务fine-tune pre-trained parameters。
- 我的理解就是,1直接利用 word embedding作为 feature,并且之后也不会再改变这个embedding。而2则也会利用下游任务的 loss back-propagate 回生成词向量的模型,即词向量也会训练而改变。(==是这样么==)
-
这个团队认为,现有的方法限制了pre-trained representation 的 power,尤其是fine-tuning,因为现有模型是单向的,这限制了网络在pre-train过程中的选择(==啥子意思==)就比如OpenAI GPT这篇工作。
- 这篇工作里,他们就在改进 fine-tuning based approach。随机把 input 中的一些 token mask 掉,目标是通过context (left and right)预测原本的 vocabulary id,
Related Work
这部分这篇paper 主要介绍了3种经典 pre-training 方法。
- Unsupervised Feature-based Approaches ELMo
- Unsupervised Fine-tuning Approaches OpenAI GPT
- Transfer Learning from Supervised Data ImageNet
BERT
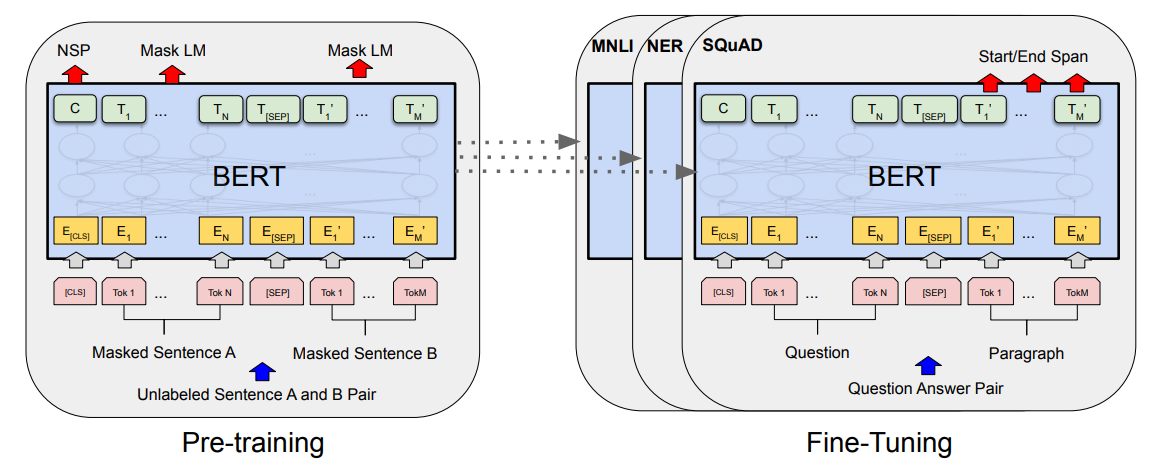
两个步骤,pre-training 和 fine-tuning
- pre-training: 用unlabel data 在不同的 pre-training task 上训练
- fine-tuning: 用pre-trained parameter initialize,然后用label data 在下游任务上fine-tune。每个下游任务有各自的fine-tuned 模型,即使初始化一样为一样的参数。
BERT一个独特的性质是:在不同任务上都有一致的的 architecture,在pre-trained architecture和 下游任务的architecture。
-
Model Architecture
多层的双向Transformer encoder,几乎和2017 Vaswani的一样。
表示:
- $L$ Transformer 的层数
- $H$ hidden size
- $A$ self-attention head 的数量
-
Input/Output Representations
-
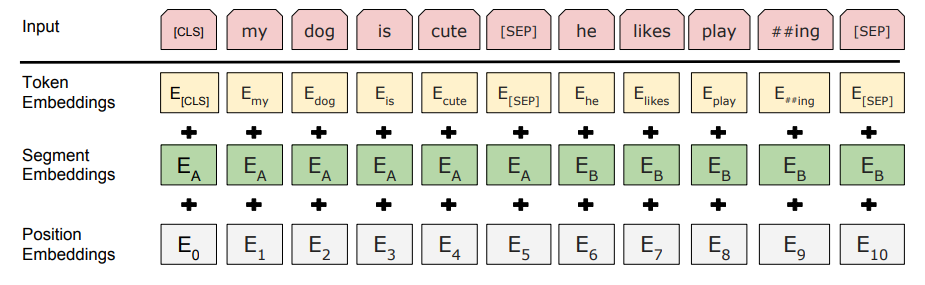
为了能处理各种下游任务,BERT 能把单个句子或是<Question, Answer>这样的成对儿句子 represent
-
他们使用 WordPiece embeddings, 有30000词汇,任何sequence的开头都是一个 [CLS],就当是一个特殊的分类字符。这个[CLS] 字符的 final hidden state 可以被用作分类任务(句子的feature embedding)。成对儿的句子被[SEP] 字符隔开,并且,会给每个token 加上一个learned 的embedding 来indicate 他是属于Question 还是Answer。
-
对于一个token的输入representation =
-
输出:$C$, $T_*$
-
Pre-training BERT
用两个无监督任务 pre-train BERT,Masked LM 和 Next Sentence Prediction
-
Masked Language Model (MLM): mask 掉句子中的一些单词(~15% -> [MASK]),然后去预测他们。最终的被mask掉的位置上的token的 hidden vector 经过所有词表的softmax。这样的一个缺点:造成了pre-training 和 fine-tuning的mismatch,(什么mismatch呢?[MASK]这个token 在fine-tuning中是不会出现的)。为了缓解这个问题, 在mask 单词的时候,有80%用[MASK] 替换,10%用一个random token 替换,10%不变。最后用cross entropy loss预测origin token。
-
Next Sentence Prediction(NSP):很多的下游任务比如QA,或Natural Language Inference (NLI) 都是基于对两个句子关系的理解建立的。这里他们就在尝试首先构建很多的句子pair作为训练集,选取句子对儿的时候,50%B句子就是A句子的后一句(标记为IsNext),50%B句子是一个random 句子(标记为NotNext)。之前[CLS] token 对应的final hidden vector用来做next sentence prediction(NSP)(这里我查了一下,虽然这个任务名字叫next sentence prediction,但这里的预训练并不是让模型去预测后面的句子,只是预测B句子是不是A句子的后一句,二分类问题,叫这个名字我怀疑是说这个训练后续对这个任务有帮助?)之前的工作只有句子的embedding 被传到了下游任务,但是BERT可以传递所有参数,去初始化模型参数。
-
Pre-training data:简单一说,BERT的pre-training用了 BookCorpus (800M words)和English Wikipedia (2500 M words)。wiki上他们只截取文字形式的文章。
Fine-tuning BERT
Fine-tune BERT 比较straight forward,因为内部的Transformer 内部的self-attention机制能使 BERT model 很多下游任务,我的理解就是我们可以拿来BERT的输出作为好多任务的输入,比如[CLS] 的final hidden state 用来分类,各个token的representation当作word embedding。
对于任意一个任务,我们只需要plug in input 和 output,然后进行end-to-end的参数训练。输入的时候,可以处理大致4个种类的输入:
- sentence pairs in paraphrasing
- hypothesis-premise pairs in entailment
- question-passage pairs in question answering
- a degenerate text-$\phi$ pair in text classification or sequence tagging. (就是直接不输入后一个句子B)
输出的时候,token representation就用作token level的任务,[CLS] 的representation就用做分类任务、情感分析等。
与pre-training 相比,fine-tuning 较快
Experiment
11个NLP 任务,下次一定……